This partnered project involved designing and implementing a 5-layer Convolutional Neural Network (CNN) for translating audio data into visual spectrograms.
Being able to identify sounds could be very useful in technology for those that are hearing impaired. This real-world application was a key motivator for creating and training a network that could correctly classify a range of urban sound audio clips.
Dataset: urbansound8k
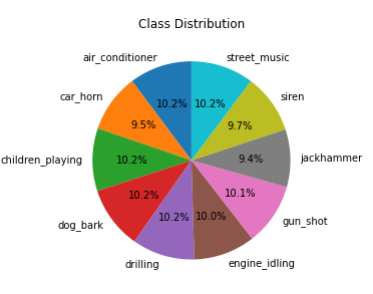
There were 10 classes within this audio dataset. The distribution can be seen below:
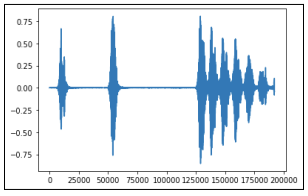
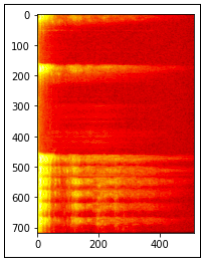
We formatted the data by translating the audio waves into spectrograms and then inputting the spectrogram images into the CNN model. Below is an example audio wave of a dog barking, and its accompanying spectrogram:
Next, we trained and evaluated using 10-fold cross validation, and the best accuracy was saved for any future testing.